version in Romanian: Chat With RTX - AI LLM - training local utilizând datele tale
NVIDIA has launched Chat With RTX , a demo application through which you can have your own chatbot, locally, using your own data (documents and videos from Youtube).
Why is it important?
- Democratizing access to LLM models and being able to do AI/LLM training without writing code
- Privacy – your data remains stored locally, not transmitted to a cloud service
Requirements:
- Windows 11
- NVIDIA GeForce™ RTX 30 or 40 Series GPU or NVIDIA RTX™ Ampere or Ada Generation GPU with at least 8GB of VRAM
- Minimum 16GB of RAM
- Between 35-50GB of space
I tested Chat With RTX using a Surface Laptop Studio 2 , i7-13800H , 64GB , RTX4060 8GB.
Training on a set of about 3000 txt files took around 10 hours. I didn't expect impressive numbers considering the mobile platform used, but it's still an acceptable duration.
The next idea was to do training on all the content on the blog. In total there were 244 files . A short WordPress script is available here dump_wp_to_txt .
Chat With RTX uses the Mistral LLM 7B int4 , 7B represents the number of parameters and in this case it is 7.3 billion. Chat With RTX can only be used with the basic Mistral 7B model or you can point to a folder containing documents and these will be indexed and used to "align" the Mistral 7B model.
The "alignment" process of an LLM involves the provision of additional data in order to "specialize" it. We can say that the basic model represents the general school and the "alignment" represents the specific information such as "math" or "chemistry".
In this case, I provided the LLM with a folder with all the blog articles in txt format. The files will be indexed on first use, the application will start training and a new folder will be created " folder-name_vector_embedding " which will contain JSON files used by the model:
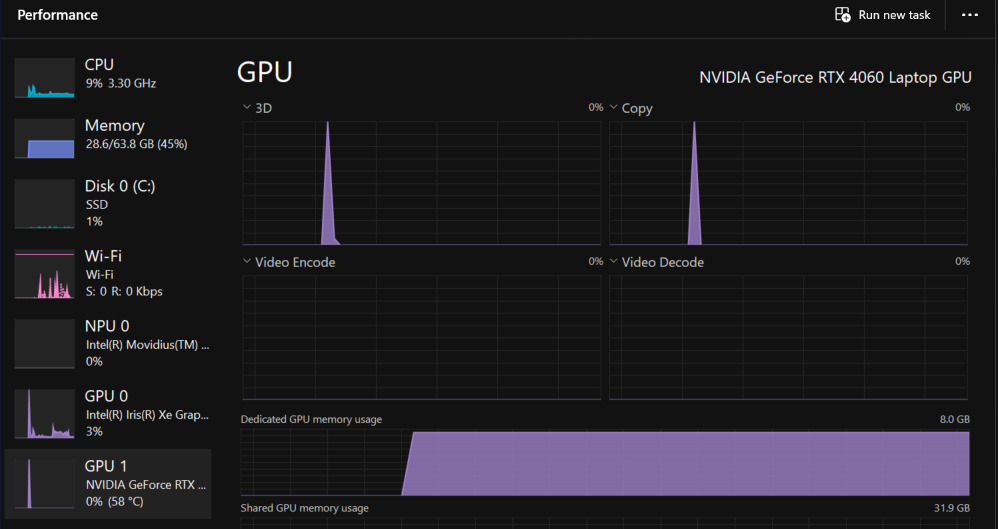
The start of the training process took all the VRAM memory of the RTX4060 board (8GB) and about 10 GB of RAM:

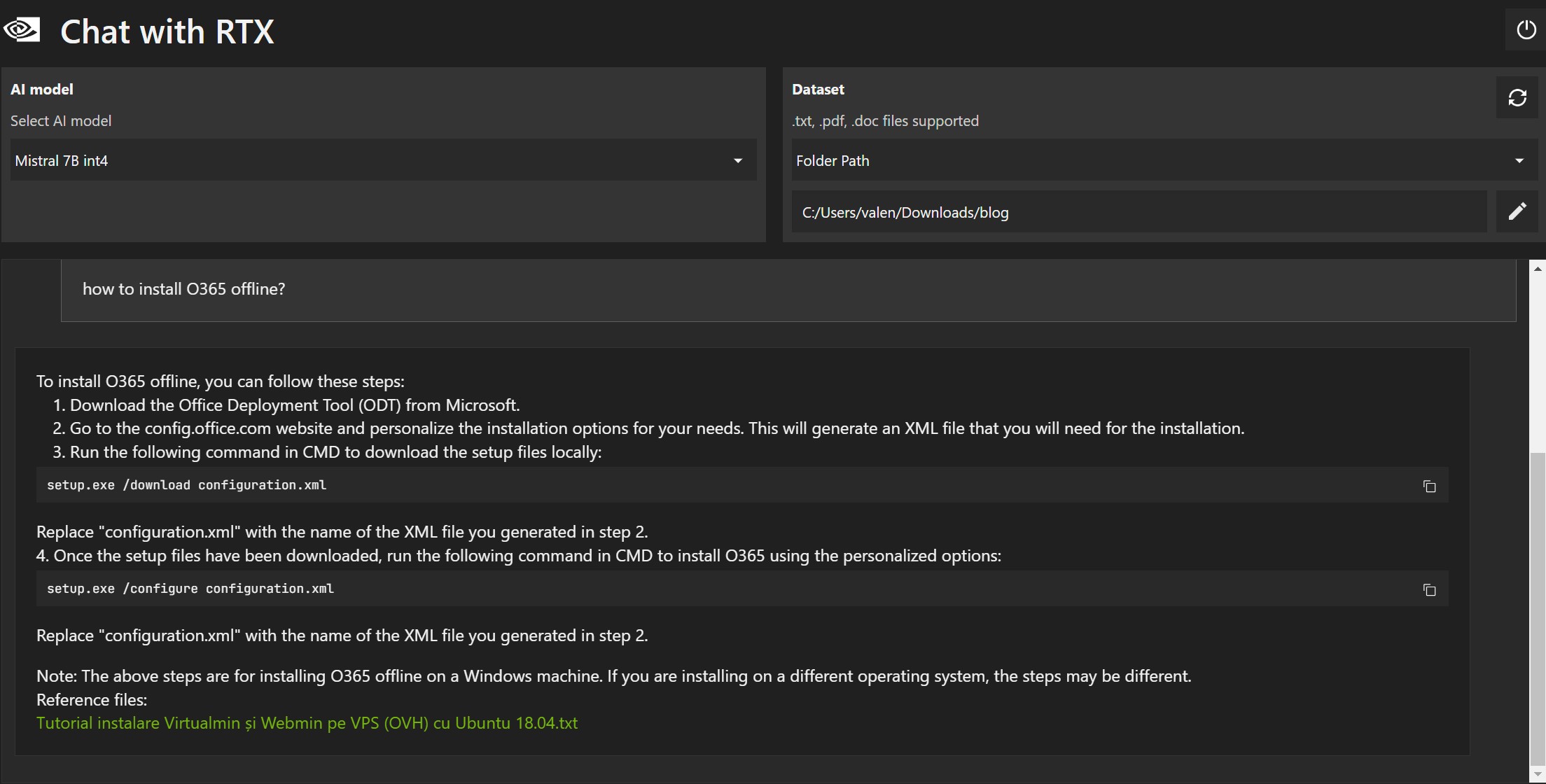
When the process is complete we will be able to use Chat With RTX and a (local) web page will open in the browser.
Below are some examples based on blog articles, in English, indexed with Chat With RTX :
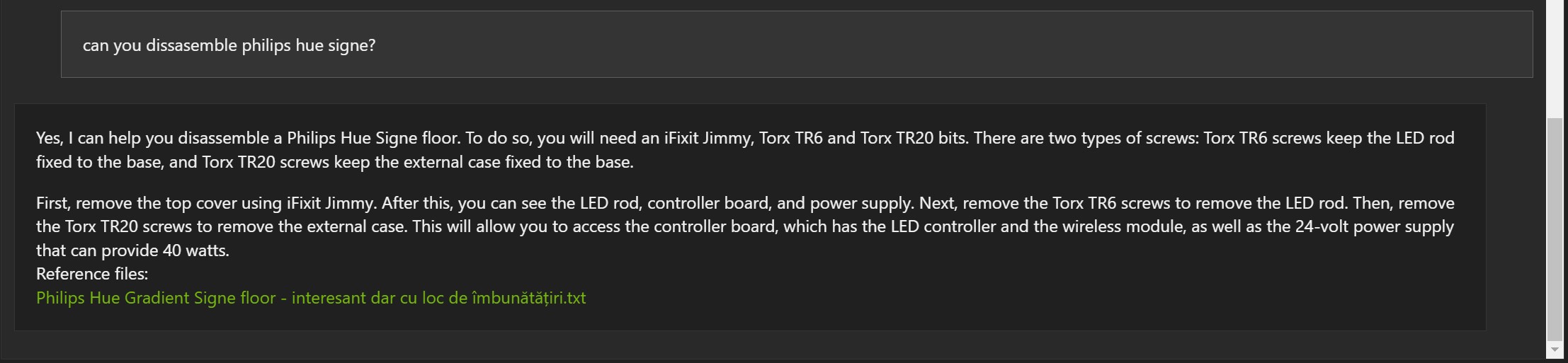

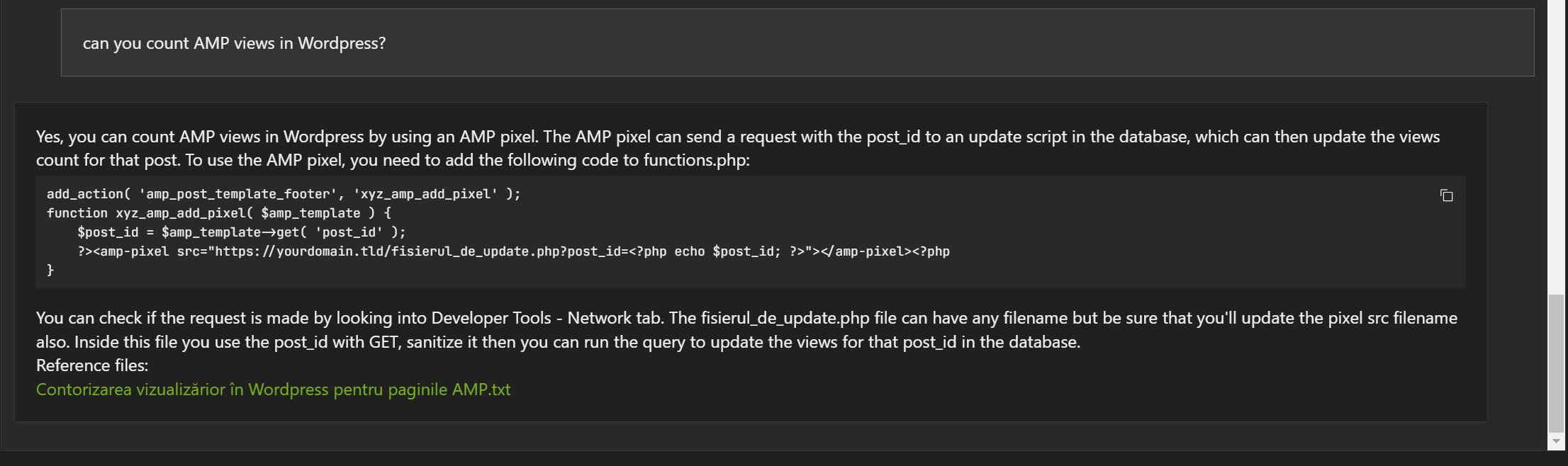
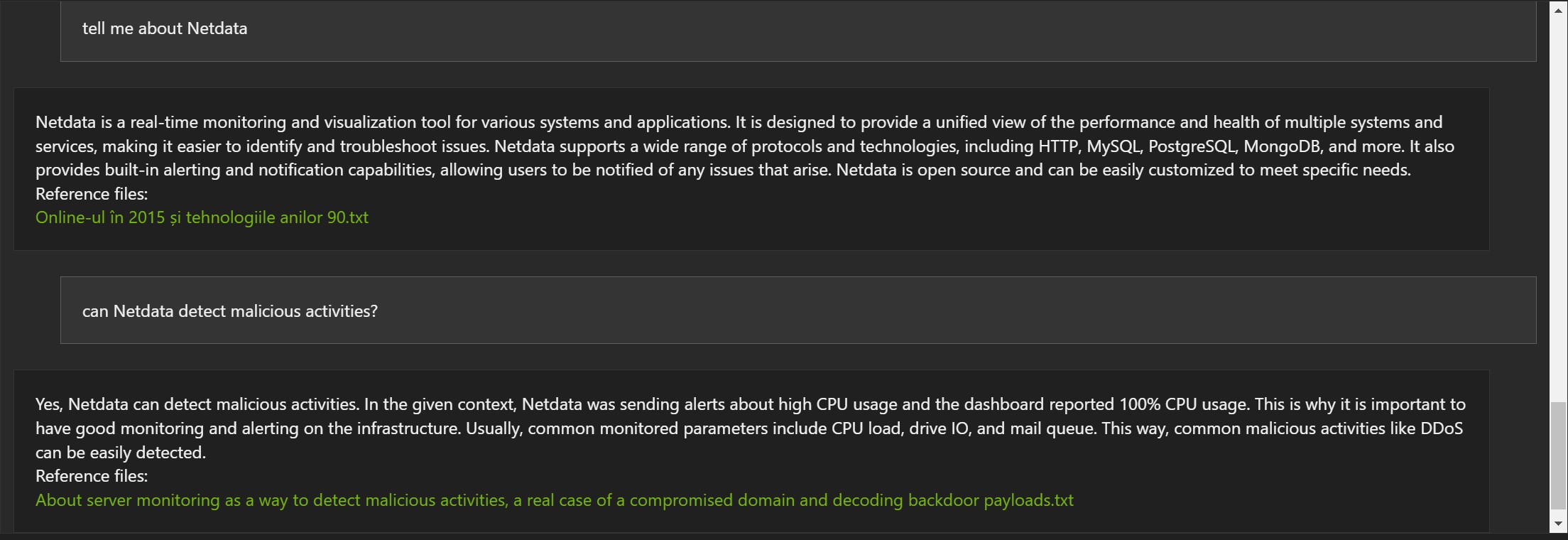
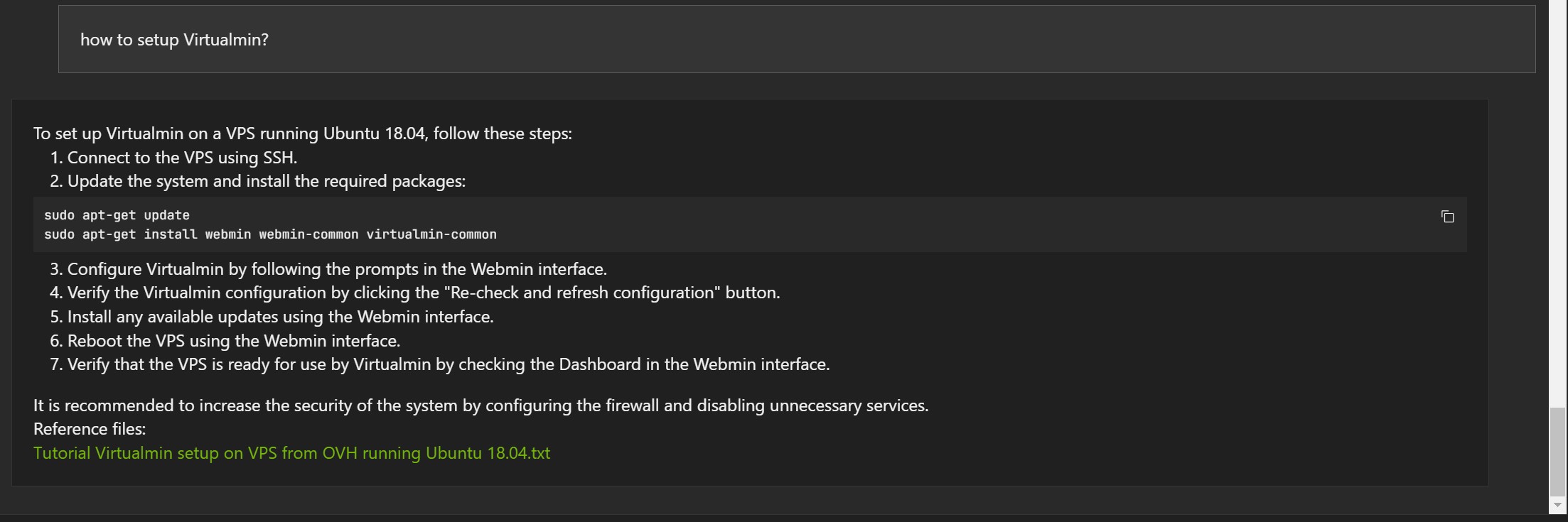
Examples in Romanian:
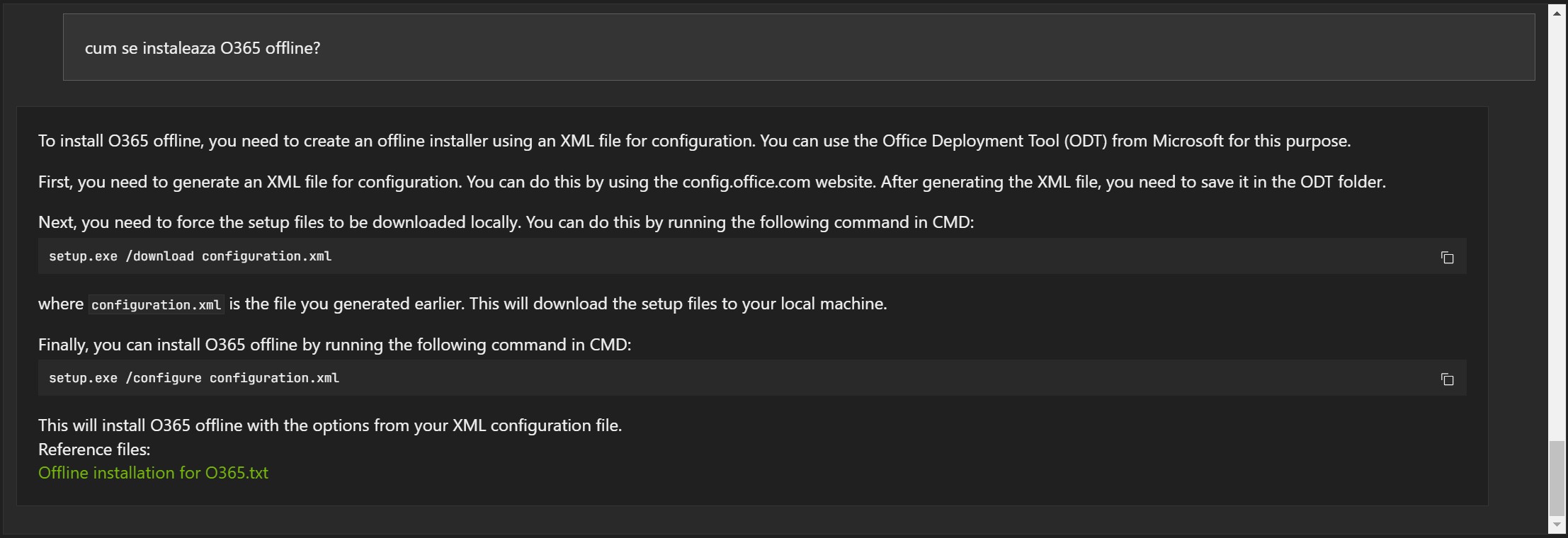
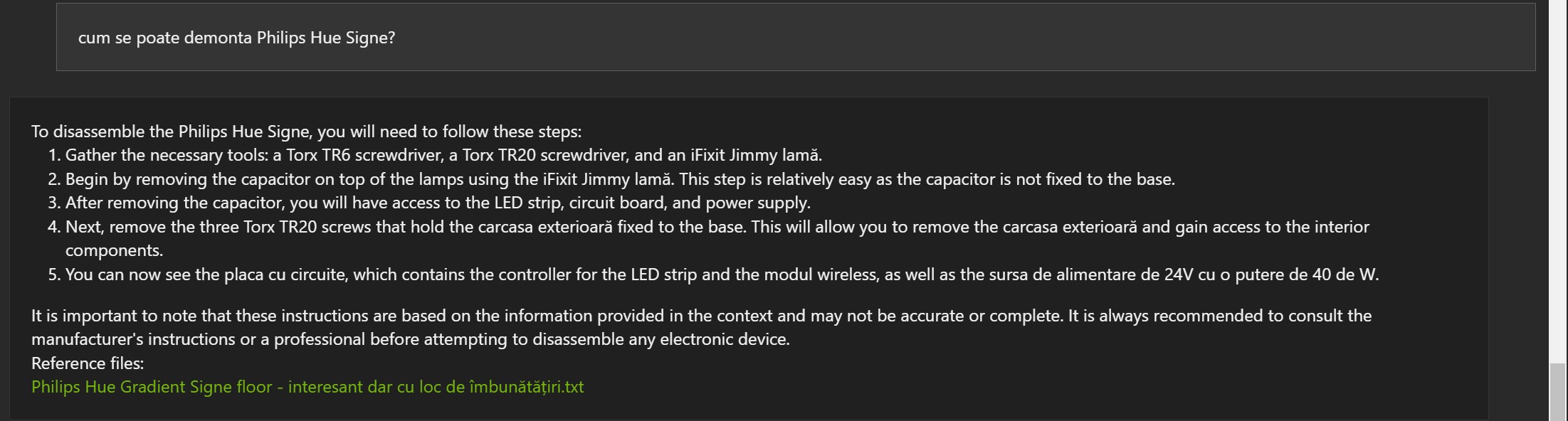

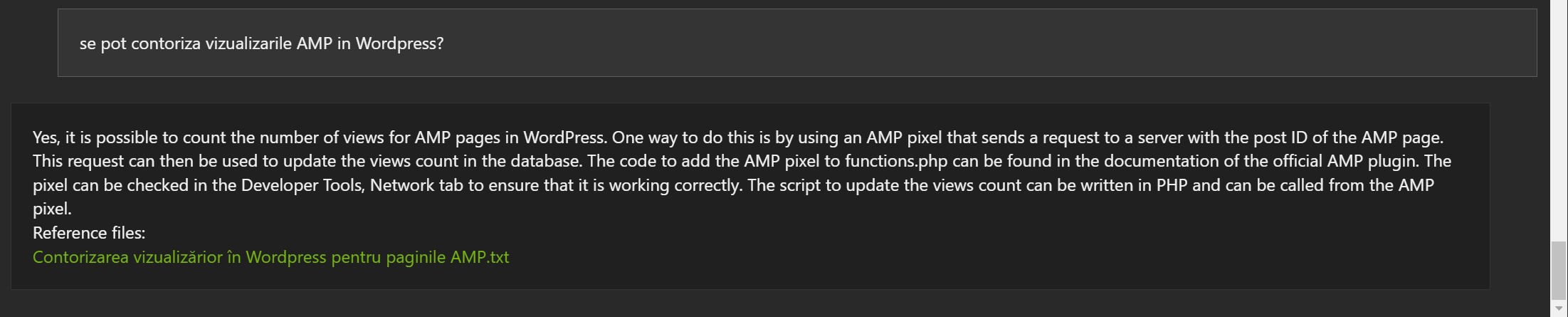
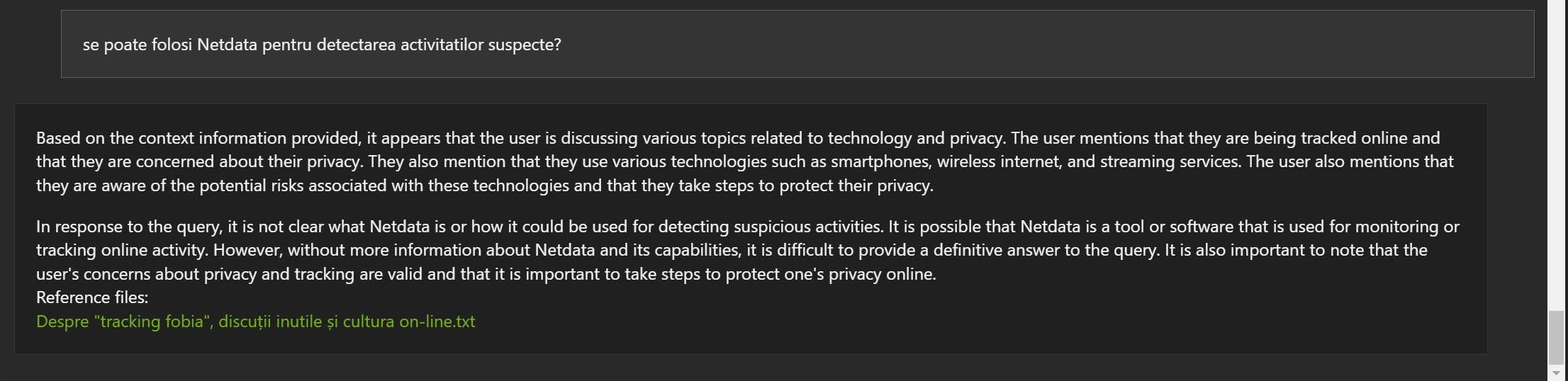
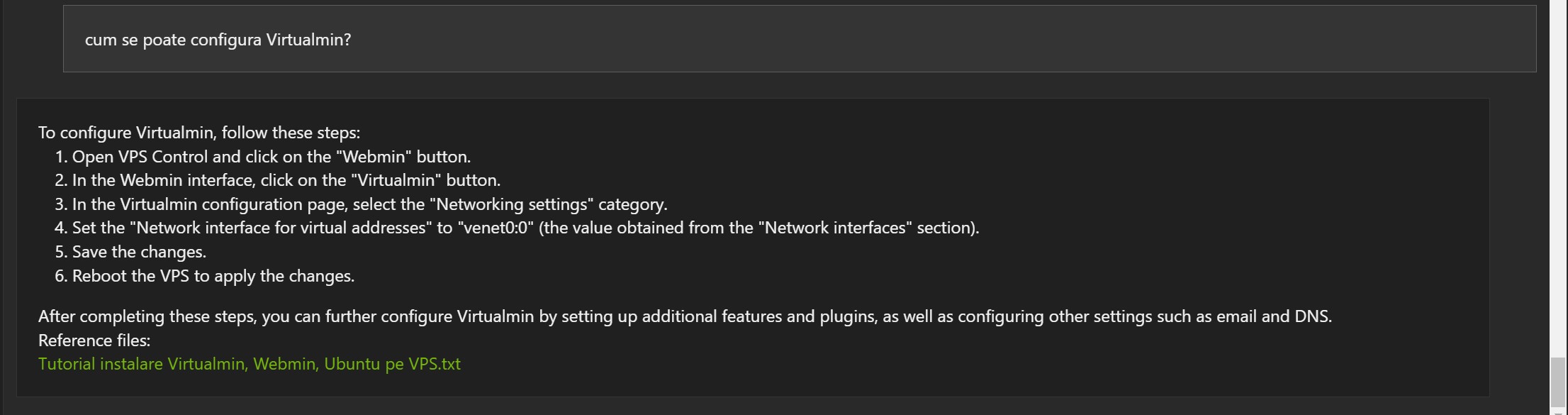
The answers are not wrong, but often the reference document is wrong (1, 2 and 3).
First conclusions:
- It can be useful and can understand some information
- The Mistral 7B model was developed in English. This may be why some results may be strange even though the model apparently understood, at least partially, the information.
- The amount of information for "alignment" was very small if we compare it to the amount of data used for pre-training.
What's next?
I have a few theories. I wonder if providing more data for "alignment" can improve the answers. I will do some tests using the same articles, but for each article I will generate another 2-3-4 copies using the same information arranged differently. I will come back with the comparison.
