
While developing the TraceIT AI ICT user support agent, I encountered a challenge. The bot performs well with multiple conditional nodes but struggles with reverting to generative responses or deciding when to use a tool to investigate an issue. I’m seeking a way to enhance the decision-making process, which could be improved by implementing a confidence-based decision mechanism based on the details of the generative responses.
In Azure AI Foundry, APIs provide additional data, such as confidence scores, which help refine decision-making by quantifying the reliability of generated responses.
I’m looking to implement a similar confidence-based decision mechanism in Copilot Studio’s generative AI node to improve the agent’s ability to dynamically select actions or responses based on the confidence level of the generated output.
Let's start with what is available in the response from a "Create generative answers" node in Copilot Studio:
{
"IsSydneySummarized": false,
"Text": {
"CitationSources": [
{
"Id": "1",
"Name": "lorem.txt",
"Text": "text",
"Url": ""
},
{
"Id": "2",
"Name": "lorem2.txt",
"Text": "text2",
"Url": ""
}
],
"Content": "AI reply",
"MarkdownContent": "AI reply"
}
}As evident, the response lacks a confidence score or additional metadata to validate its accuracy.
If you propose adding an AI node in Copilot Studio to evaluate responses, this approach is unfeasible due to a key limitation:
generative AI nodes in agent flows cannot directly access the agent’s knowledgebase (e.g., SharePoint or Dataverse).
This restriction prevents the nodes from comparing responses against validated data, making it impossible to generate reliable confidence scores within the node itself.
What if we pass the AI-generated response back to the AI node and ask it to assess whether the response aligns with the user’s query?
By providing the relevant knowledge directly to the node, we bypass its inability to access the agent’s knowledgebase. The node can then evaluate the response and assign a confidence score. This approach, known as iterative refinement or recursive validation, involves looping the AI’s output back to the agent (or another AI instance) for review, ensuring the response is accurate, relevant, and aligned with the user's request.
Let's add a new node - tools - new prompt:
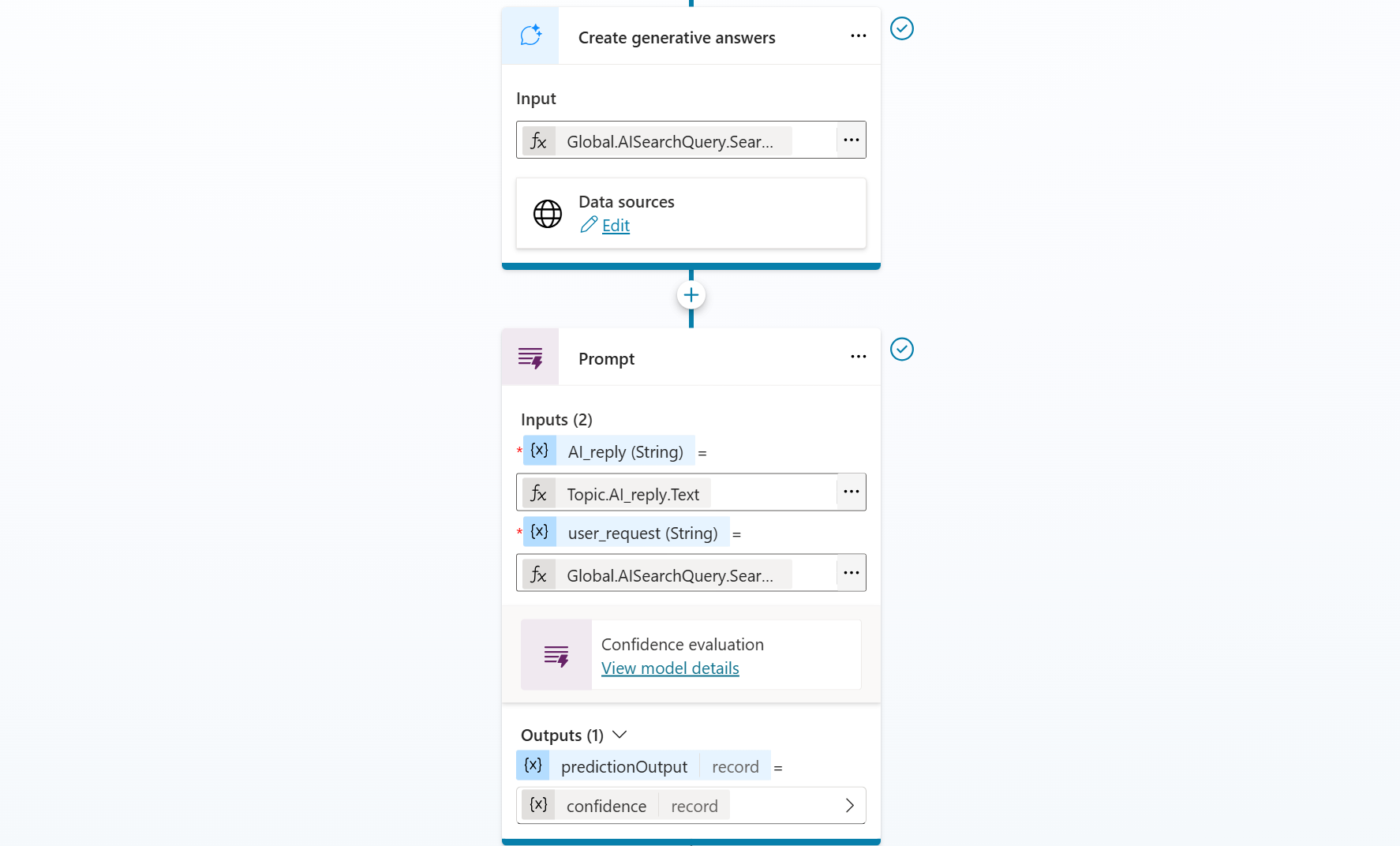
The node configuration accepts two inputs: the AI-generated response from the previous node and the user’s query. It produces a single output: the confidence score.
The prompt is something in line with:
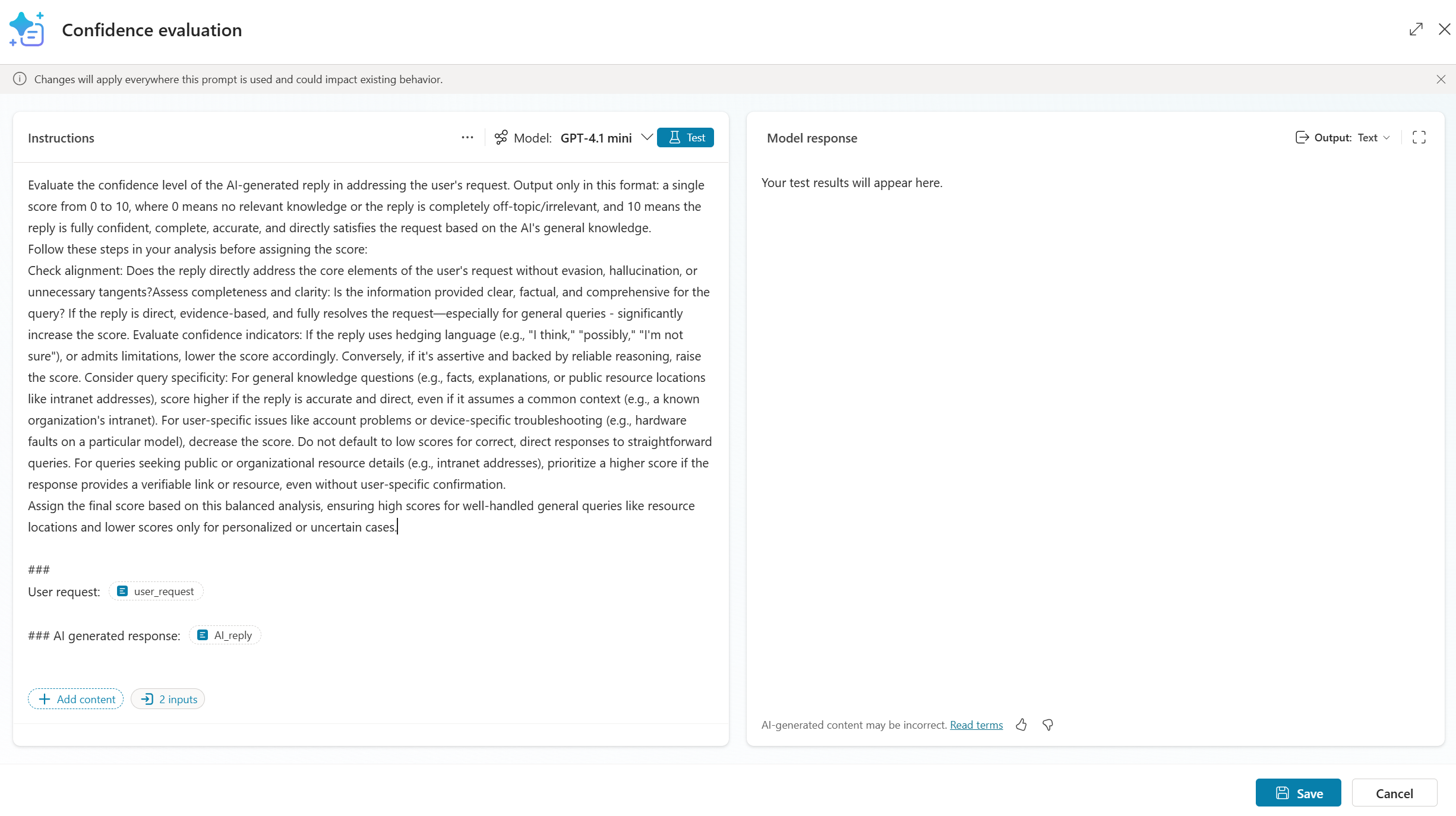
Evaluate the confidence level of the AI-generated reply in addressing the user's request. Output only in this format: a single score from 0 to 10, where 0 means no relevant knowledge or the reply is completely off-topic/irrelevant, and 10 means the reply is fully confident, complete, accurate, and directly satisfies the request based on the AI's general knowledge.
Follow these steps in your analysis before assigning the score:
Check alignment: Does the reply directly address the core elements of the user's request without evasion, hallucination, or unnecessary tangents?Assess completeness and clarity: Is the information provided clear, factual, and comprehensive for the query? If the reply is direct, evidence-based, and fully resolves the request—especially for general queries - significantly increase the score. Evaluate confidence indicators: If the reply uses hedging language (e.g., "I think," "possibly," "I'm not sure"), or admits limitations, lower the score accordingly. Conversely, if it's assertive and backed by reliable reasoning, raise the score. Consider query specificity: For general knowledge questions (e.g., facts, explanations, or public resource locations like intranet addresses), score higher if the reply is accurate and direct, even if it assumes a common context (e.g., a known organization's intranet). For user-specific issues like account problems or device-specific troubleshooting (e.g., hardware faults on a particular model), decrease the score. Do not default to low scores for correct, direct responses to straightforward queries. For queries seeking public or organizational resource details (e.g., intranet addresses), prioritize a higher score if the response provides a verifiable link or resource, even without user-specific confirmation.
Assign the final score based on this balanced analysis, ensuring high scores for well-handled general queries like resource locations and lower scores only for personalized or uncertain cases.###
User request: user_request### AI generated response: AI_reply
Add a conditional node to evaluate the confidence score for your specific case. If the score is above the threshold, return the generative answer. If it's below the threshold, request more details or redirect to another topic if the intent is recognized.
Featured image generated with Grok Imagine
